Configuring Connection Pool with Spring R2DBC
A product-minded engineer with solid engineering principles, strong background in Java and curiosity to explore new things.
Edit on 10 March 2022:
- Edited the article and example code to use five initial connections and a maximum of ten connections to give a better example of connection pool sizing.
This article is the second part of my first article related to Spring Boot R2DBC. If you haven't checked it out, please check out: Reactive Spring Boot Application with R2DBC and PostgreSQL
Connection Pooling
After successfully configuring your Spring Boot with Spring Data R2DBC, you probably want to launch it to production without any performance hiccup. Unfortunately, it's not as straightforward as you would like. You will need to use connection pooling.
Connection pooling is a way to store and reuse a connection to be reused later, avoiding the expensive cost of creating a connection for each use.
Before we implement connection pooling, let's try to do some basic benchmarks to see whether or not it improves our application performance.
Playing Around with R2DBC Pooling Performance
There are multiple ways to load test our application, you can even use Apache Benchmark directly from your terminal with the ab command. But this time, I'd like to explore a tool called K6.
Load Testing with K6
We're testing an API to insert a hundred records into our database. This API is going to be a write-heavy operation to stress the database.
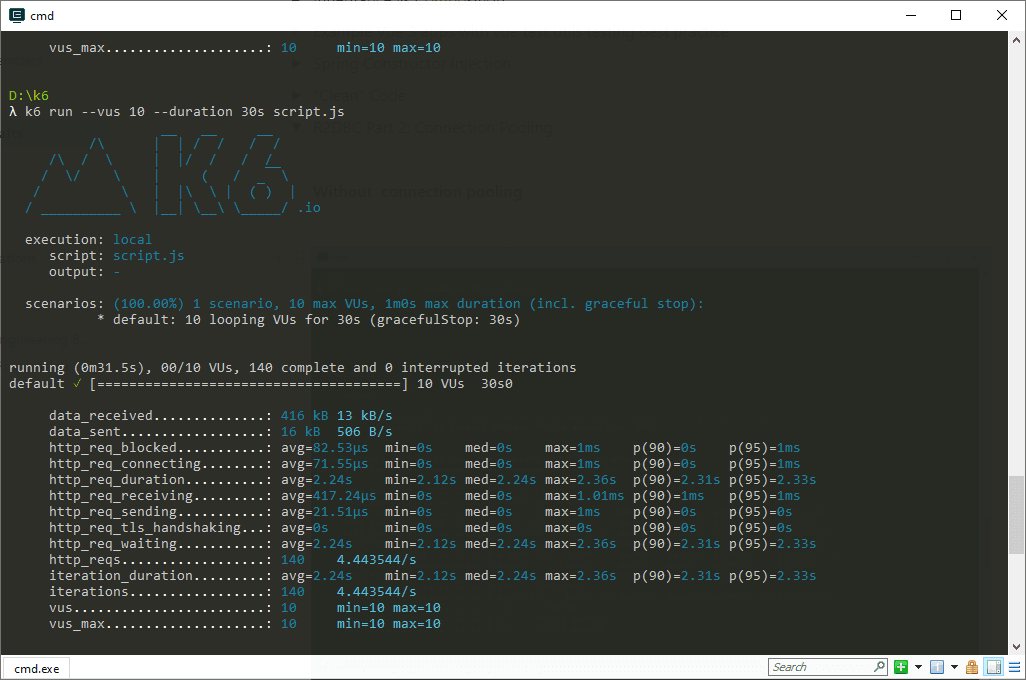
Without Connection Pooling
Without connection pooling, we only get 140 requests completed, with the 95th percentile of 2.33s.
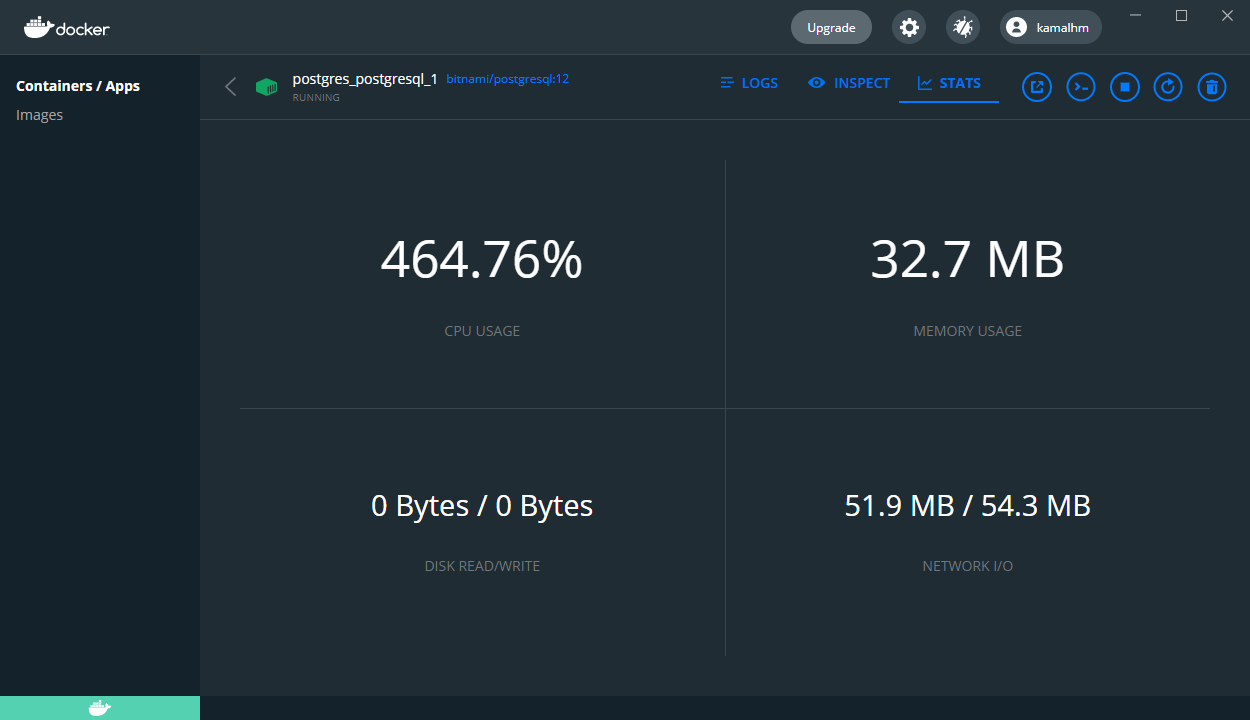
I also noticed that the docker instance responsible for running the database CPU usage spiked dramatically.
Implementing Connection Pooling in Spring Boot R2DBC
In Spring Boot applications that use blocking connection to a database such as JDBC, connection pooling is usually handled by a popular library called HikariCP. Luckily, Spring Data R2DBC already includes a connection pooling option that we can use just by enabling it from our properties.
To enable it, you can add the below properties to your application.properties file, and R2DBC will be able to pool the connections to our database! Easy right?
spring.r2dbc.pool.enabled=true
spring.r2dbc.pool.initial-size=5
spring.r2dbc.pool.max-size=10
As you can probably guess, these properties will initiate the pool with five connections ready to use, and when needed, it can scale up to a maximum of 10 connections. Now then, let's try our benchmark again.
With Connection Pooling
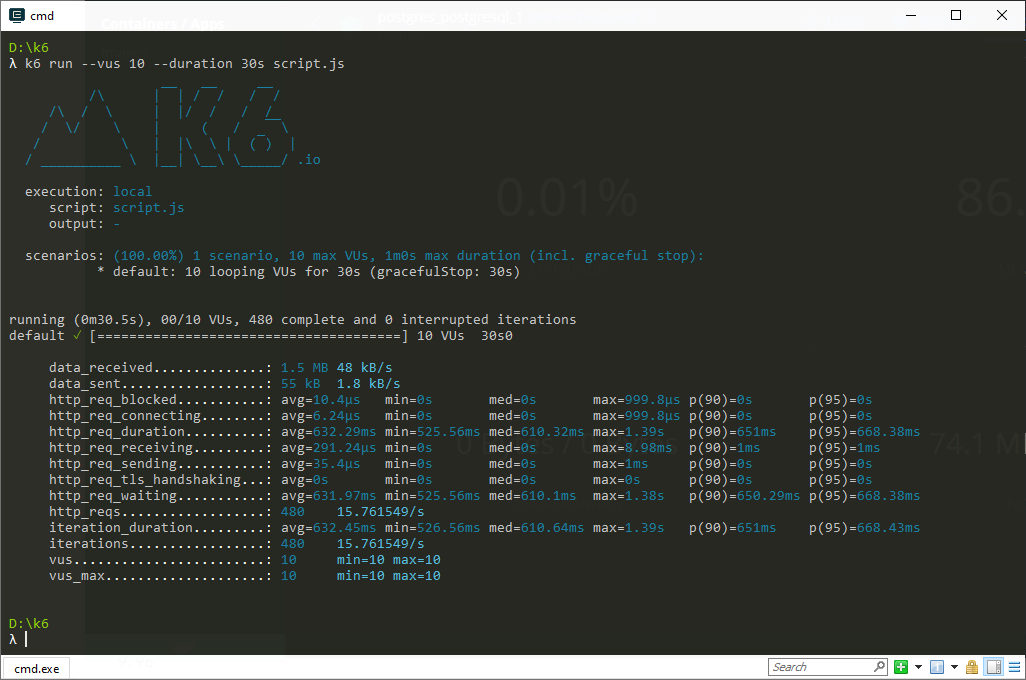
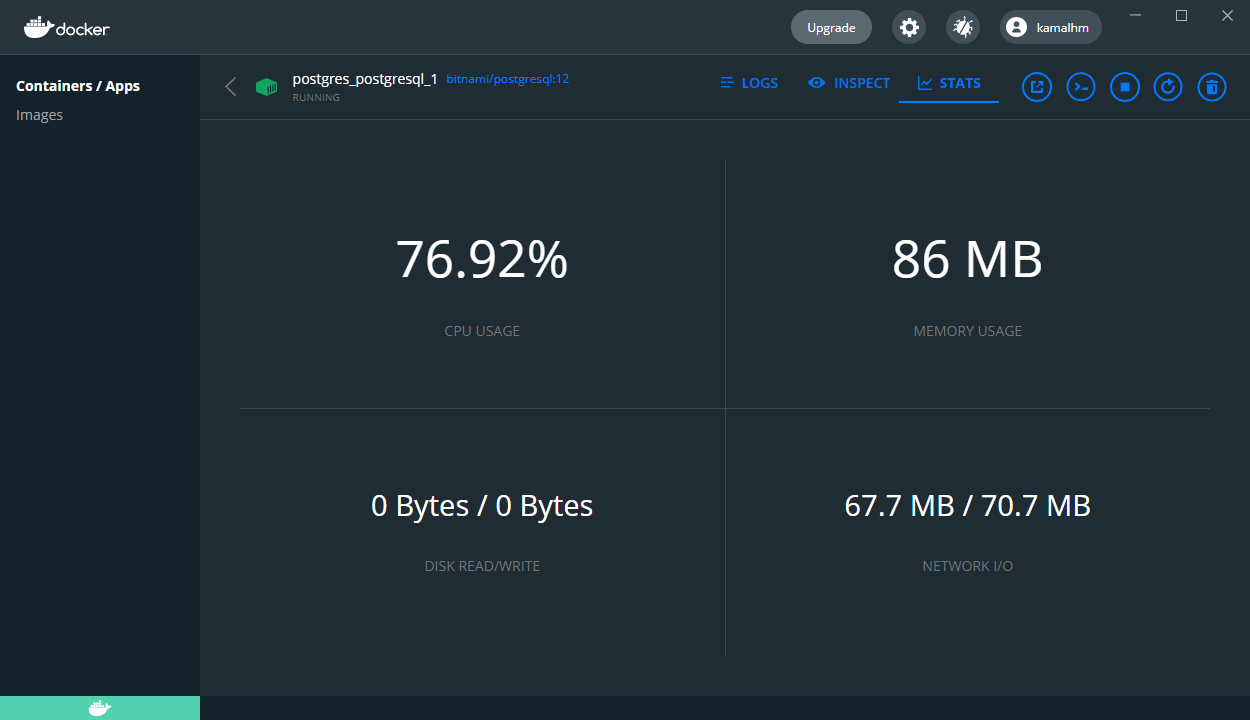
The result is striking. We completed 480 iterations of the requests with connection pooling, increasing throughput by almost 3.5x and reducing our 95th percentile latency to 668ms. That's an almost 4x latency improvement! When we look at the docker instance, the CPU usage also stays comfy at around 76% usage. Enabling connection pooling improved the performance by almost 4x and reduced our database load significantly.
Connection Pool Sizing
After seeing an awesome performance improvement above, you might be tempted to try and increase the connection pool even further. After all, if we can get 4x improvement with ten connections, we should get even better performance with a 20 connection pool. Or at least that's what we expect. But sorry to burst the bubble. The short answer is no.
If you'd like to learn further about connection pool sizing, please refer to this awesome article on pool sizing by the author of HikariCP himself: https://github.com/brettwooldridge/HikariCP/wiki/About-Pool-Sizing
Conclusion
We have learned how easy it is to enable connection pooling on an R2DBC project and its impact on your application performance. So don't forget to set it up whenever you're configuring your application!
As usual, you can see the source code for the project at https://github.com/kamalhm/spring-boot-r2dbc

